Unicodeは全世界10万文字を超える文字集合です。
一方、UTF-8やUTF-16はUnicodeの符号化方式のことを言います。
この符号化方式であるUTF-8とUTF-16について、エンディアンとBOMというバイトオーダの概念、さらにサロゲートペアと呼ばれる拡張仕様という色々と複雑な話があります。
ここではUnicode周りの、こういった仕様について分かりやすくまとめたいと思います。
1.文字集合と符号化方式
はじめに、一般にいう「文字コード」について、
「文字コード」とは「文字集合」と「符号化方式」の両方をまとめた概念的な言い方で、厳密には
・文字集合(character set)
・符号化方式(character encording scheme)
に分かれます。詳しくは別ページにまとめています。
2.当初のUnicodeの文字集合、符号化方式(Unicode1.0)
当初のUnicodeの文字集合
Unicodeの文字集合についてはUnicode1.0の当初、当初世界の全言語を包括するにも関わらず、16ビット固定で、2^16(=65,536文字) で制定されました。
世界の全言語が何故65536文字で足りると思ったのでしょうか?これが、後にサロゲートペアという難解な仕組みを作り出します。
当初のUnicodeについて詳しくUTF-8、BOM他
UTF-16
16ビット(0000〜FFFF)でUnicodeの文字集合を表現する符号化方式で、完全にUnicodeの文字集合と1対1でマッチする符号化方式でした。※当初は
オプション設定として、エンディアン、BOMがあります。
~ エンディアン ~
UTF-16は全文字16ビット符号化としたのですが、当時主流のSJIS、EUC-JPは、半角8ビット、全角16ビットで符号化されていました。
現在この程度の大きさはどうでも良い話ですが、当時のCPU処理能力では捨て置ける話ではなく、UTF-16は半角も全角も16ビットなので、SJIS、EUC-JPと比較して負荷が大きいと捉えられました。
このため、少しでもCPUの負荷を減らすべく、考えられたのがエンディアンです。
UTF-16は16ビット=2バイト符号なので上位バイトと下位バイトの順番をどうするかを設定できるようにして、適切に設定すれば、全文字16ビット符号でもSJIS、EUC-JPに劣らない処理速度となることを目指しました。
エンディアン詳細
エンディアンはUTF-16独自の技術ではなく、元々あるバイト並び順(バイトオーダー)を示すコンピュータ用語です。
例えば「00000000」「11111111」という8ビットずつ合計16ビット=2バイトで表現するデータがあったとして
「00000000」→「11111111」の並び順を ビッグエンディアン (Big Endian)
「11111111」→「00000000」の並び順を リトルエンディアン (Little Endian)
と呼びます。
本来、人間の目から見ると、「00000000」→「11111111」となる「ビッグエンディアン」が普通なのですが、
コンピュータは小さい桁から処理する為、「00000000」→「11111111」でデータをもらうと、全てのデータをもらってからでないと処理できないです。
対して「11111111」→「00000000」となる「リトルエンディアン」なら「11111111」を受け取った時点から処理開始できます。
ところが、最近はどちらでも良くなり機種、規格により様々となりました。
例えばTCP/IPのようにIPアドレスやMACアドレスなど大量のバイトをいちいち並べ替えているとかえって効率が悪いため「ビッグエンディアン」で処理すると決められました。※ネットワークバイトオーダと言います。
これにより、ビッグエンディアン、リトルエンディアンどちらが速いかは処理を行う環境次第となりました。
~ BOM(ByteOrderMark) ~
ファイルの先頭16ビット(2バイト)に記載するもので、エンディアンの判別に利用されます。
・ビッグエンディアンの場合「FE FF」
・リトルエンディアンの場合「FF FE」
をファイルの先頭に記載します。
BOMが付与されていない場合はビッグエンディアンとして扱われます。
~ まとめ (UTF-16ファイル形式の種類) ~
下図の通り、3種類に分かれます。
| BOM |
エンディアン |
例:A |
| BOM付 |
ビッグエンディアン |
FE FF 00 41 |
| BOM付 |
リトルエンディアン |
FF FE 41 00 |
| BOM無 |
ビッグエンディアン |
00 41 |
尚、Windows や Javaで "Unicode" といえば「UTF-16、BOM付、リトルエンディアン」をデフォルトとしています。
UTF-8
上記UTF-16の説明でも書きましたが、UTF-16は半角全角ともに16ビット符号で、SJIS、EUC-JPが半角文字は8ビット、全角文字は16ビットで符号化しているのに対してサイズが大きいです。
負荷を減らす目的でエンディアンを考慮したところで、環境にもよりますが、影響は軽微です。
そこで、根本的な対策としてUTF-8符号化があります。
UTF-8ではSJIS、EUC-JPと同等レベルで圧縮する目的で、UTF-16のASCIIコード範囲(0000-007F)について、8ビットで符号化することにしました。
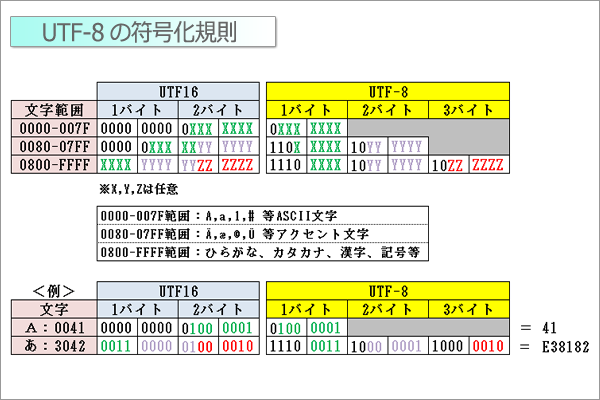
上図の通り、ASCIIコード範囲は8ビット(1バイト)に圧縮されますが、反面、日本語は24ビット(3バイト)となり、UTF-16の16ビット(2バイト)より効率が悪くなります。
このことから英数の割合が多い場合はUTF-8、日本語が多い場合はUTF-16がコンピュータの処理効率が良い符号化方式ということになります。
~ エンディアン ~
UTF-8ではこの規格はありません。1バイト符号についてはオーダーはないからです。
~ BOM(ByteOrderMark) ~
UTF-8では不要です。ビッグエンディアン一択だからです。
UTF-8 VS UTF-16 どっちがメジャー?
バイト数の違いによる効率はさておき、UTF-8、UTF-16どちらも符号化方式の違いだけで全てのUnicode文字を表現できます。
ではどちらの符号化方式がメジャーかというともちろんUTF-8です。
英語圏から見てUTF-16はサイズが大きくで効率が悪いのです。
UTF-16は廃れるか、あわよくばUTF-8と共存というレベルの符号化方式だと思います。
その他のUnicode符号化方式
他に、UTF-7という符号化方式があります。UTF-16をBASE64エンコード(英数文字だけにする符号化方式)して7ビットで表現するものです。
過去のメール環境の互換として考えられましたが、今般のメール環境ではBASE64エンコードをほぼ必要としないので、今後使用される符号化方式ではありません。
さらにUTF-32という符号化方式があるのですが、これは拡張後の話なので、後に書きます。
3.拡張後のUnicodeの文字集合、符号化方式(Unicode3.0)
2^16(=65,536文字)では、案の定、領域が足りなくなり、Unicode3.0で大幅に拡張することになりました。
このときに採用された拡張に対応する符号化方法がサロゲートペアと呼ばれる方法です。
ネットワークでいうIPv4の枯渇問題に対処するNATやIPマスカレードと発想は良く似ています。
拡張後のUnicodeの文字集合
下図のように、元々の65,536文字のエリアを0面目:BMPと位置付け、さらに65536文字の16面を追加することで、文字集合を拡張することとなりました。
新しく追加する16面のコードは10000〜10FFFF。
この追加により最大文字数は65,536文字から1,112,064文字に増加しました。
65,536(BMP) - 2,048(サロゲートコードポイント) + 65,536 × 16(追加面) = 1,112,064
尚、元々の65,536文字のエリア内D800〜DFFFについては、サロゲートコードポイント(後に説明するサロゲートペアで使用する領域)として、文字登録しないことになりました。
この追加面に登録された文字は、漢字で言うとほとんど常用で使用しないレベルの漢字だけで、これだけでいうと追加面の利用頻度はそれほど高くないのですが、この追加面に今後「絵文字」がどんどん追加されるとのことです。

拡張後のUnicodeについて詳しくUTF-8、BOM他
UTF-16 サロゲートペアによる拡張領域の符号化対応
この文字集合の拡張により、文字集合と文字符号化を1対1とする場合、21ビット必要となりました。
※上位2ビット、00,01,02,03,04,05,06,07,08,09,0A,0B,0C,0D,0E,0F,10を表現するため、既存の16ビットに加えて、5ビット必要です。
しかし、UTF-16を規格変更して、21ビット体系にしてしまうと、根本的に符号化体系が変わることになり、過去のUTF-16とまったく互換性がなくなります、つまり総文字化けとなります。
これを避けるために考えられた方法が、サロゲートペアという符号化方法です。
~ サロゲートペア ~
サロゲートペアは、前提として16ビット単位で文字を判断する符号化方法です。
まず、既存の文字集合のD800〜DFFFまでの範囲に文字を割り当てないサロゲートコードポイントと呼ぶ特殊な領域を作りました。
次にD800〜DBFFを上位サロゲート、DC00〜DFFFを下位サロゲートに分けました。
そして下図の通り、上位サロゲートと下位サロゲートの組み合わせ(ペア)で、10000〜10FFFFの範囲を表現します。
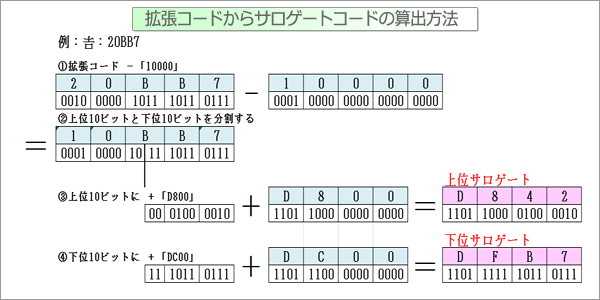
このように上位サロゲートと下位サロゲートの合計32ビットで符号化するため、更にサイズが肥大化することになったのですが、
・あくまで追加文字が32ビットになっただけで、元々の文字は16ビットのまま
・元々の文字符号化をそのまま利用しているので拡張によって元々の文字が文字化けすることはない。
・仮にサロゲートペア未対応のフォントであった場合、サロゲートコードポイント上に文字が
登録されていないので、認識できない文字として「?」「?」と上下サロゲート2文字分表示される※
だけの影響ですむ。
と高いメリットがありました。
※同様に、strlen関数のような文字数、バイト数を数える関数で、非対応の場合、2文字、4バイトになってしまいます。
UTF-8
元々の符号化部分(ASCII:8ビット、日本語:24ビット)は、符号変更もなく、影響ありません。
サロゲートペアで対応する拡張部分はUTF-16同様32ビット(4バイト)で符号化します。
~ MySQL の UTF-8 mb4 ~
4バイト対応のUTF-8規格です。つまりサロゲートペアで表現する拡張文字を扱える規格です。
MySQLは、5.5.33までは4バイト対応していなかったのですが、UTF-8という規格名でした。
そのため、それまでのUTF-8(3バイトまで対応)と区別して、「UTF-8 mb4」の名前で規格追加しました。
~ Oracle の CESU8 ~
UTF-8規格とほぼ同様ですが。サロゲートペアの扱いがUTF-8と若干違う規格です。
UTF-32
文字集合と文字符号を1対1にするために考えられた規格です。拡張文字も元々の文字も21ビット体系であれば1対1で符号化可能ですが、きりが悪いので32ビットとしています。
この規格であれば、文字集合と文字符号を1対1にできますが、後付けであり、混乱を招く原因とも言えます。互換性は完全に失われます。
ネットワークでいうIPv4の枯渇問題に対処するためのIPv6と考え方は似ています。
4.テキストエディタの保存オプション
ここまでUnicodeの符号化について考えてきましたが、非常に複雑化しているように思います。
この影響でテキストエディタの保存オプションについても、パソコンに詳しい方が見ても、すぐに理解できなくなってきていると思います。
以下、メモ帳について考えます。
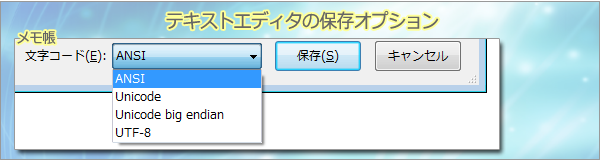
~ メモ帳 ~
| 文字コード |
説明 |
| ANSI |
Windowsに採用されたSJISの拡張CP932のことです。 |
| Unicode |
UTF-16、BOM付、リトルエンディアンのことです。 |
| Unicode big endian |
UTF-16、BOM付、ビッグエンディアンのことです。 |
| UTF-8 |
|