今回は、グループ化による集計についてまとめます。
(2)、(3)で抽出、(4)で表示をまとめましたが、今回は、今までの概念とは少し違う抽出と表示になります。レコードを一部又は全部でグループ化し、グループごと合計、最大値、最小値、平均値を計算します。
グループ化による集計
まず大前提ですが、グループ化を利用して表示した抽出結果(すべての抽出結果に当てはまることですが)は、その時点でプライマリーキー及びインデックスの効果は失われています。二次利用の際は注意が必要です。
1-1.基本的な考え方
~ 例1 ~

テーブルAの「KIND」項目でグループ化してみます。
例1
select
A.KEY,A.KIND,A.VALUE
from A
group by A.KIND;
~ 結果 ~

WHEREを指定している訳でもないのに1レコードに絞られて表示されますが、内部では、問題なく2レコード抽出できています。ただ「KIND」項目でグループ化したので、SQLは、この場合KIND=0のどちらのレコードを表示したら良いのか分からないので、KIND=0の先頭行を表示しているのです。これを代表値と呼びます。この代表値となるレコードはテーブルの並び順つまりプライマリキー、インデックス順で決まります。
~ 例2 ~
テーブルAの「KIND」項目でグループ化して、「KIND」項目名と合計項目として「VALUE」項目を表示します。
例2
select
A.KIND,SUM(A.VALUE) as VALUE
from A
group by A.KIND;
~ 結果 ~

このように、通常は代表値を表示せず、グループ化の対象項目と、集計値のみを表示します。しかし、複雑なSQLの場合、代表値を利用したいがためにあえてグループ化する場合もあります。
~ 例3 ~
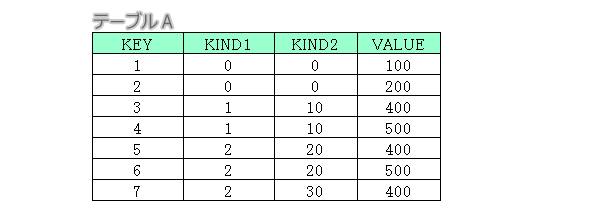
WHEREでKIND1<>0を抽出した上で「KIND1」、「KIND2」項目でグループ化して、「KIND1」、「KIND2」項目名と合計項目として「VALUE」項目を表示します。
例3
select
A.KIND1,A.KIND2,SUM(A.VALUE) as VALUE
from A
where A.KIND1<>'0'
group by A.KIND1,A.KIND2;
~ 結果 ~

このように、WHEREで抽出した上で複数のグループ化を使用する等、複雑な指定にも対応できますが、基本的な仕組みは簡単なものです。WHEREとグループ化が複合する場合、WHEREが先に実行されます。
1-2.HAVINGを利用した重複抽出クエリ
~ 例 ~
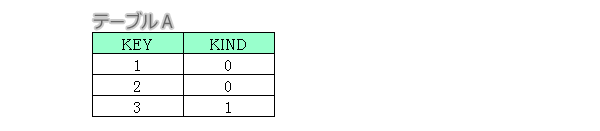
テーブルAの「KIND」項目でグループ化し、KINDの項目が重複する「KIND」の値を表示します。
例
select
A.KIND
from A
group by A.KIND
having count(A.KIND)>1;
~ 結果 ~

HAVING句はグループ化されたものをさらにグループごとレコードの状態を確認する場合に使用します。この場合、count関数を使用して、各グループ内のレコード数を数え、2レコード以上あるグループを対象として値が表示されます。先ほどのWHEREと違いHAVINGは後に実行されるのがポイントです。
1-3.集計関数
グループ化の際に利用する主な集計関数は、以下程度です。
| 集計関数 |
意味 |
| count() |
グループ化した(対象項目)の件数 |
| sum() |
グループ化した(対象項目)の和 |
| max() |
グループ化した(対象項目)の最大 |
| min() |
グループ化した(対象項目)の最小 |
| ave() |
グループ化した(対象項目)の平均 |