文字化けは作成者の文字コードと使用者の文字コードの違いによって発生するものです。例えば「UTF-8」で作成されたファイルをブラウザで開く場合、通常は「UTF-8」と自動認識されますが、何等かのエラーで自動認識されなかった場合、文字化けが発生します。
この場合、「UTF-8」であることを明示的にブラウザに伝えれば、文字化けは直ります。
ところが、文字コードを正しく指定しても「?」や「・」になってしまう文字があります。
これが「文字なし」です。
長くシステムに携わっていると、必ずこの「文字なし」問題に悩まされることがあります。
特に現場では氏名についてこの問題が起こりやすいです。印刷すると「?」になっていたというように、思いがけず問題になることがあります。
多くのサイトではこのような文字をエントリー段階で防ぎ、登録できないように制御しますが、特に氏名についてはどうしてもそのまま登録しなければならないケースもあります。
そんな、文字化けよりも深刻な「文字なし」についてまとめたいと思います。
そして、「ちょっと違う文字」、「全く違う文字」になるケースも、まれにありますので、併せてまとめます。
0.はじめに(文字コードとは)
はじめに、一般にいう「文字コード」について、おさらいしたいと思います。
「文字コード」とは「文字集合」と「符号化方式」の両方をまとめた概念的な言い方で、厳密には
・文字集合(character set)
・符号化方式(character encording scheme)
に分かれます。文字コードの代表であるSJIS、UTF-8は実際は下図の通り符号化方式のことを言います。
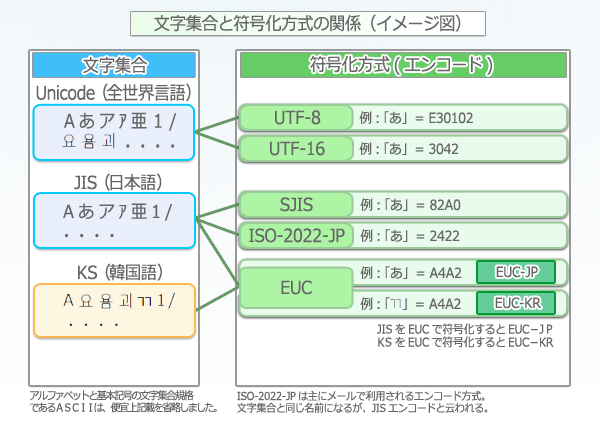
「文字集合」とはその名の通り文字の集合体。分かりやすく言うと、1ファイルに全文字が入力されている大きなファイル、というイメージです。
「符号化方式」とは文字集合から文字コードを用いて該当の文字を呼び出すための仕組みです。
一般的に、「文字集合」は各パソコンにインストールされています。そして、例えば、メールには指定した「符号化方式」の文字コードのみが入ります。送られたメールを相手方が開くとその符号化方式に従って、自身のパソコンの「文字集合」を参照します。
この仕組みにより、いちいちファイルサイズの大きい「文字集合」を送らなくても文章の伝達できるという昔ながらの仕組みです。(※最近ではネットワークの速度向上、CDNの普及により、Webフォントという「文字集合」を毎回やりとりする仕組みも普及しています。また、WordやPDFはフォントをファイル内に埋め込みます。)
反面、この方式だと相手パソコンの「文字集合」に依存するので、文字化け等のトラブルが発生するリスクを持つ仕組みとも云えます。
そして、もう一つ。「フォントファイル」についてです。
現状、文字集合規格は、UnicodeとJISの2種類です。
そして、例えばWin10の標準フォントである「游ゴシック」や「メイリオ」、「MSゴシック」など。これらはUnicodeとJISどちらの文字集合規格にも対応しています。
そして、UTF-8、UTF-16、SJIS等すべてのエンコードに対応します
しかし、Unicodeで規定されている全外国語が、各フォントにすべて含まれているかというと、違います。Unicode対応と言っても、収録されている文字は、JIS文字集合だけだったり、これは、フォントごとに違います。
JIS文字集合といっても、JIS X 0208:1990、JIS X 0213:2004、Adobe-Japan1-7など様々な規格があります。
つまり、文字集合だけではなく、フォントごとに文字の有り無しがあります。
1.「文字なし」となるパターン
1-1.文字コード変換により、文字が存在しない場合
ここではUnicodeを「UTF-8」、JISを「SJIS」として以下記述しています。
文字コードの変換で発生する「文字なし」件数をまとめると以下の通りとなります。
先に結論ですが、UTF-8を使用しましょう。全ての文字を網羅しており、「文字なし」の原因になりません。
「文字なし」となる件数については、あくまで目安程度に考えて下さい。どこまでのUnicodeの範囲を比較の対象にするのか、何のフォントを使用するかによって大幅に件数が変わるからです。
下表の件数については、件数の根拠をまとめてしていますので、興味のある方は確認して下さい。
|
UTF-8 |
SJIS |
| UTF-8 → |
- |
有:18,867文字 |
| SJIS → |
無 |
- |
UTF-8 → SJIS 変換で「文字なし」になる18,867文字の詳細
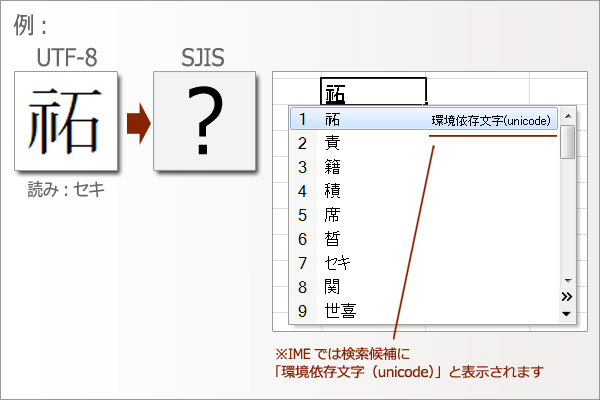
~ UTF-8 → SJIS 変換で「文字なし」になる18,867文字 ~
1-2.フォントが対応していない場合
フォントに文字が収録されていない場合に発生する問題です。この問題は古いフォントを利用している場合に良く起こります。この場合は「?」や「・」にもならず、そしてスペースにもならず、空文字になりますので注意が必要です。
1-3.Vista以上で追加された文字をXP以下で見る場合
Windows Vista以降、Windows XPに比べて約900文字追加されました。これによりWindows Vista以降で作成されたドキュメントをWindows XPで見た場合「文字なし」が発生します。
対象は以下の6フォント(MS明朝、MS P 明朝、MSゴシック、MS P ゴシック、MS UIゴシック、メイリオ)です。
追加された文字は「驒」、「㐂」、「沪」、「𡈽」、「琢」、「簞」、「吞」等です。
1-4.ユーザーが作成した外字、販売されている外字の場合
当然、ユーザーが作成した外字、販売されている外字をインストールした場合は端末に依存し、別端末で見た場合、「文字なし」となります。
XP当時は、氏名を入力する場合に文字が足りず、自分で外字を作成したり、外字パッケージ製品である「ダイナフォント」等をインストールしたりしていましたが、「文字なし」となるリスクが大きい手法であることと、Windows Vista以降の文字追加により、最近あまり外字は利用されなくなりました。
2.「ちょっと違う文字」となるパターン
2-1.Vista以上でフォントフェイスが変更された文字をXP以下で見る場合
この件は有名な話で、Vistaリリース後は特に大混乱になりました。2017年現在でも、今だにその混乱が続いています。
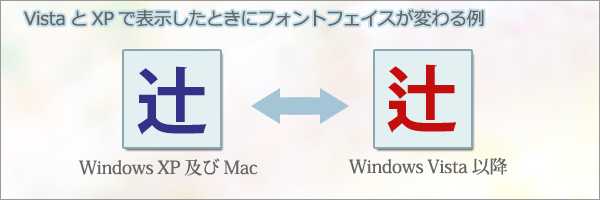
上記「辻」を含む122文字が「ちょっと違う文字」になります。
対象は以下の6フォント(MS明朝、MS P 明朝、MSゴシック、MS P ゴシック、MS UIゴシック、メイリオ)です。
~ 「ちょっと違う文字」になる122文字 ~
溢淫厩噂恢晦徽汲卿僅櫛屑倦捲巷榊杓哨摺撰噌揃樽歎捗擢堵屠叛廟庖儲愈冤喩嘲囀扁槌楢樋榔牙祇笈祁甑灼煎煽穿瀦溺瀞灘禰秤瀕瞥漣煉疼猷芦茨葛翰翫薩薯藷蛸蝕箭腿箸蔽蔑篇蓬籾簾筵篝逢迂襖迦諺逗詮遡遜辿註辻賭遁謎這逼謬豹迄訝飴鰯餌鞄饗鵠鯖錆酋鎚鄭鱒餅鑓騙鴉鞘
~ 参考:何故こんな混乱となったのか ~
日本語の規格についてJIS90→JIS97→JIS2000→JIS2004というように都度改定が加えられています。
このJISに対しXPではJIS90に準拠していましたが、「Vista以降JIS2004に対応するために、この122文字についてフォントフェイスを変更した。」というマイクロソフトからのアナウンスなのですが、
何故JIS委員会は、今更混乱を招く可能性の高い字体の変更を行う必要があったのか、何故マイクロソフトは大手フォント会社と同じく、「MSゴシック、MSゴシックN」というようにJIS90のフォントとJIS2004のフォントを分けず上書きしてしまったのか、今でも言われています。
因みに、混乱を緩和するためマイクロソフトからJIS90に対応させるモジュールが配布されましたが、Windows7までで、Windows8以降は配布されません。
2-2.Unicodeの類似変換の場合
UTF-8 → SJIS 変換において、環境により、以下の図のように「文字なし」とならず類似文字に変換されてしまうことがあります。
~ Unicodeの類似変換の例 ~
| Unicode |
文字(元) |
SJIS |
変換文字 |
| 00C0 |
À |
0x41 |
A |
| 00C1 |
Á |
0x41 |
A |
| 00C2 |
 |
0x41 |
A |
| 00C3 |
à |
0x41 |
A |
| 00C4 |
Ä |
0x41 |
A |
| 00C5 |
Å |
0x41 |
A |
この例では、ラテン文字のアクセント記号付について、該当する文字コードがSJISにないため、類似のラテン文字に置き換わっています。アメリカでは基本、アクセント文字を使用しませんので、問題の無いケースかもしれませんが、イギリスではアクセント記号を使うので問題になるかもしれません。
3.「全く違う文字」となるパターン
3-1.CP932とSJISの差分。機種依存文字
この件はもう過去の事になるかもしれません。UTF-8を使用すれば、何等、問題のない話です。
SJISの際は、以下のとおり注意して下さい。
「SJISとCP932」の違い
先ずこの件を理解するために「SJISとCP932」の違いを認識する必要があります。
元々SJISという文字コードがあり、マイクロソフトがSJISをOSの標準文字コードに採用した際に、「コードページ 932 (CP932)」という管理番号を与えられました。
単にWindowsに採用されたSJISの管理番号がCP932だというだけの話で、「SJIS=CP932」であり、本来、何等CP932という呼び方自体、意識する必要はありませんでした。
ところが、いろいろな変遷がありいくつか独自に文字が追加されてしまい、「CP932>SJIS」になってしまいました。
~ 参考 追加された文字~
・JIS X 0208の非漢字(1983年追加文字)の一部(重複10文字)
・NEC特殊文字(重複22文字)
・NEC選定IBM拡張文字(374文字)
・IBM拡張文字(388文字)
これにより、CP932は「Windowsの使用するSJIS」として通常のSJISと区別されるようになりました。
それでも少し文字が増えている程度なので、通常は特にCP932と呼ぶこともなく、SJISと呼ばれています。
「全く違う文字」となるパターン
このときMACも一部フォントでSJISを採用したのですが、同様に文字を追加する際、連携せずに各々違う文字コードに割り振りました。
マイクロソフトとアップル、別メーカーの話ですし、確かに合わせるいわれはない話なのかもしれません。
ただ、結果的には、SJISの拡張部分いわゆるCP932とSJISの差分についてWindows、Mac等機種により違う文字が表示されることが、あり得るようになりました。
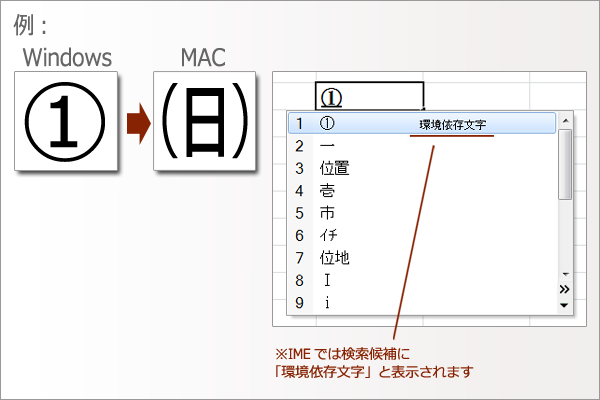
~ 「全く違う文字」となる例 ~
| SJIS |
文字(Windows) |
SJIS |
文字(MAC) |
| 8740 |
① |
8740 |
㈰ |
| 8741 |
② |
8741 |
㈪ |
| 8742 |
③ |
8742 |
㈫ |
| 8754 |
Ⅰ |
8754 |
㈵ |
| 8755 |
Ⅱ |
8755 |
㈼ |
| 8756 |
Ⅲ |
8756 |
㈽ |
参考:件数の根拠
「1-1.文字コード変換により、文字が存在しない場合」の件数根拠です。
以下の条件、環境で件数を算出しています。
・対象としたUnicode範囲
Unicodeは多言語文字コードであり、英語、日本語に加えてアラビア語、シリア語等、全世界の言語を全て包括する文字コードです。Unicode5.0にて10万語を既に突破しています。対してSJIS、EUC-JPに含まれるのは概ね英語、日本語だけです。
このため比較対象をあわせるため、できる限り、英語、日本語、及び記号のみに絞るようにしています。
具体的には、以下の通りですが、JIS X 0213の規定している文字を含むUnicodeの「文字ブロック」を網羅するようにしています。
~ 比較対象 26,347文字の詳細 ~
| Unicode範囲 |
文字ブロック |
対象
文字数 |
備考 |
| 0000~007F |
C0制御文字及び基本ラテン文字 |
94 |
制御文字:33文字除く |
| 0080~00FF |
UnicodeのC1制御文字及びラテン1補助 |
94 |
制御文字:34文字除く |
| 0100~017F |
ラテン文字拡張A |
128 |
|
| 0180~024F |
ラテン文字拡張B |
208 |
|
| 0250~02AF |
IPA拡張 |
96 |
|
| 02B0~02FF |
前進を伴う修飾文字 |
80 |
|
| 0300~036F |
ダイアクリティカル・マーク |
111 |
制御文字:1文字除く |
| 0370~03FF |
ギリシア文字 |
129 |
表示不能:6文字除く |
| 0400~04FF |
キリール文字 |
256 |
|
| 1E00~1EFF |
ラテン文字拡張追加 |
246 |
表示不能:10文字除く |
| 1F00~1FFF |
ギリシア文字拡張 |
233 |
|
| 2000~206F |
一般句読点 |
52 |
制御文字:22文字除く、表示不能:18文字除く、スペース等16文字除く |
| 20A0~20CF |
通貨記号 |
28 |
表示不能:4文字除く |
| 2100~214F |
文字記号 |
76 |
表示不能:4文字除く |
| 2150~218F |
数字に準じるもの |
50 |
表示不能:10文字除く |
| 2190~21FF |
矢印 |
112 |
|
| 2200~22FF |
数学記号 |
256 |
|
| 2300~23FF |
その他の技術用記号 |
215 |
表示不能:41文字除く |
| 2400~243F |
制御機能用記号 |
37 |
表示不能:2文字除く |
| 2460~24FF |
囲み英数字 |
160 |
|
| 2500~257F |
罫線素片 |
128 |
|
| 25A0~25FF |
幾何学模様 |
80 |
表示不能:16文字除く |
| 2600~26FF |
その他の記号 |
110 |
表示不能:146文字除く |
| 2700~27BF |
装飾記号 |
160 |
表示不能:32文字除く |
| 2900~297F |
補助矢印B |
128 |
|
| 2980~29FF |
その他の数学記号B |
128 |
|
| 3000~303F |
CJKの記号及び句読点 |
57 |
表示不能:6文字除く |
| 3040~309F |
平仮名 |
93 |
|
| 30A0~30FF |
片仮名 |
96 |
|
| 31F0~31FF |
片仮名拡張 |
16 |
|
| 3200~32FF |
囲みCJK文字・月 |
174 |
表示不能:21文字、韓国語囲文字59文字除く |
| 3300~33FF |
CJK互換用文字 |
249 |
表示不能:7文字除く |
| 3400~4DB5 |
CJK統合漢字拡張A |
738 |
日本語(J~)の規定の無い5,844文字除く |
| 4E00~9FEA |
CJK統合漢字 |
20,924 |
表示不能:47文字除く |
| F900~FAFF |
CJK互換漢字 |
98 |
KS X 1001:1998(韓国)における発音重複に基づくものでかつJIS X 0213に規定される7文字、IBM拡張文字32文字、JIS X 0213における包摂基準変更に基づく変更59文字対象 |
| FE30~FE4F |
CJK互換形 |
32 |
|
| FF00~FFEF |
半角・全角形 |
173 |
半角ハングル52文字除く |
| 20000~2A6D6 |
CJK統合漢字拡張B |
302 |
JIS X 0213規定の302文字のみ対象 |
表示不能:フォントは「MS ゴシック」(Vista以降)を使用しました。この為、例えばUnicode5.0以上はフォントに含まれていませんので、表示不能として比較対象から省きました。