今回は、複数テーブルからの抽出についてまとめます。
内部結合のINNER JOINとWHERE、外部結合のLEFT JOINを中心にまとめます。
加えて大量データ操作時に要注意な結合についてもまとめます。
複数テーブルからの抽出
まず大前提ですが、プライマリーキーないしはインデックスの効いていない項目を結合条件にするのはNGです。データ数が少ないときは確かに問題ありませんが、リリース後は予想外にテーブルレコード数が増加することがありますので、よほどの事情がない限り、原則NGにするべきです。
以下の例では、特に明示しない限り、プライマリーキーないしはインデックス項目で連結しているとお考え下さい。
1-1.INNER JOINとWHEREによる内部結合
2テーブル結合
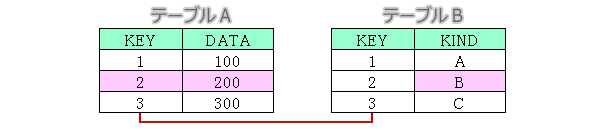
テーブルAとテーブルBをつなぎ、ピンクで着色した2行目(KEY=2)の項目を抽出する場合を考えます。
①INNER JOINでの抽出
select A.KEY,A.DATA,B.KIND
from A inner join B
on A.KEY=B.KEY and A.KEY='2';
②WHEREでの抽出
select A.KEY,A.DATA,B.KIND
from A,B
where A.KEY=B.KEY and A.KEY='2';
~ ①②結果 ~

どちらも同様の結果が抽出されます。速度も同じです。
書き方は違いますが、どちらも同じ内部結合です。
3テーブル結合
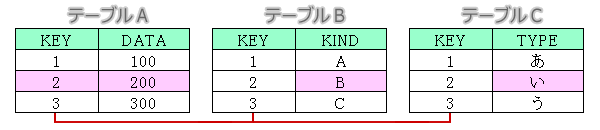
テーブルA、テーブルB、テーブルCをつなぎ、ピンクで着色した2行目(KEY=2)の項目を抽出する場合を考えます。
①INNER JOINでの抽出 A-B A-C
select A.KEY,A.DATA,B.KIND,C.TYPE
from A inner join B on A.KEY=B.KEY and A.KEY='2'
inner join C on A.KEY=C.KEY;
②INNER JOINでの抽出 A-B B-C
select A.KEY,A.DATA,B.KIND,C.TYPE
from A inner join B on A.KEY=B.KEY and A.KEY='2'
inner join C on B.KEY=C.KEY ;
③WHEREでの抽出 A-B A-C
select A.KEY,A.DATA,B.KIND,C.TYPE
from A,B,C
where A.KEY=B.KEY and A.KEY=C.KEY and A.KEY='2';
④WHEREでの抽出 A-B B-C
select A.KEY,A.DATA,B.KIND,C.TYPE
from A,B,C
where A.KEY=B.KEY and B.KEY=C.KEY and A.KEY='2';
~ ①②③④結果 ~

どの方法でも同様の結果が抽出されます。速度も同じです。
テーブル構成により①、③となる場合②、④となる場合様々ですが、この場合3テーブルが結合できてさえいれば、結合方向については、特に気にする必要はありません。
※この例ではプライマリーキー同士の結合を想定していますが、結合にプライマリーキーとインデックスの結合やレコード数の片寄りが大きい場合等、結合方向を考慮する必要がある場合もあります。
1-2.LEFT JOINによる外部結合
外部左結合は主に「メインテーブルは必ず表示しつつ、サブテーブルが存在する場合には表示する」や「差分抽出」の場合に使用します。
LEFT OUTER JOINとも書け、RIGHT JOINもテーブルの向きが逆なだけで結果は同じになります。どれを使用しても良いのですが、統一して使用しないとコードの視認性が悪くなりますので、現場の書き方を確認するようにして下さい。
メインテーブルは必ず表示しつつ、サブテーブルが存在する場合には表示する
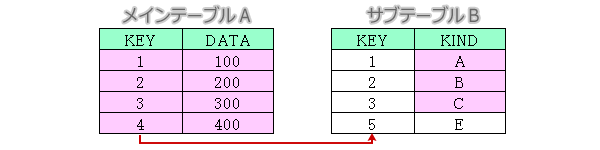
メインテーブルAとサブテーブルBを外部左結合でつなぎ、ピンクで着色したAの項目すべてとAと結合で一致する項目を抽出する場合を考えます。
LEFT JOINで抽出
select A.KEY,A.DATA,B.KIND
from A left join B
on A.KEY=B.KEY;
~ 結果 ~

差分抽出
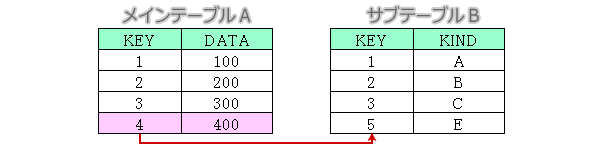
メインテーブルAとサブテーブルBを外部左結合でつなぎ、ピンクで着色したAにはあってBにはないレコードを抽出する場合を考えます。
LEFT JOINで抽出
select A.KEY,A.DATA
from A left join B
on A.KEY=B.KEY
where B.KEY is null;
~ 結果 ~

「where B.KEY is null」を書かなければ、Aと結合されたBの各項目はNULLになっています。このため、BのKEYがNULLのレコードを条件に指定すれば差分を抽出できるということになります。BのKINDがNULLのレコードを指定しても同じ結果が出ます。(プライマリーキーもしくはインデックス項目でない場合はNGですが)
よく「where B.KEY is null」の部分を「and B.KEY is null」と書いて悩まれている方がいらっしゃいましたが、結合して初めてNULLになるので、その認識は違います。andはあくまで、結合前の項目の値を条件に指定する場合に使用します。
「=NULL」ではNULLの抽出はできません。where条件にNULLを指定する場合は「is null」と書きます。
1-3.差分抽出はEXISTS、NOT EXISTSでもできる
EXISTS、NOT EXISTSを利用することで、2テーブルの差分抽出が出来ます。
select A.KEY,A.DATA
from A
where not exists(select 'X' from B where A.KEY=B.KEY);
テーブルのレコード数やガーディナリティに左右されるため、一概には言えないのですが、1-2のLEFT JOINによる外部結合を利用した差分結合よりも、この書き方のほうが、レスポンスが速いです。
1-4.内部結合と外部結合の複合パターン
内部結合と外部結合を複合することももちろん可能です。
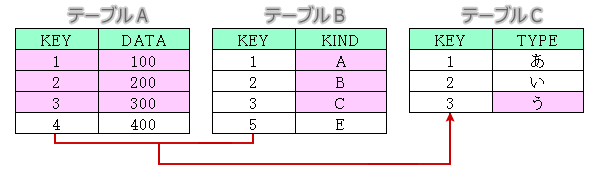
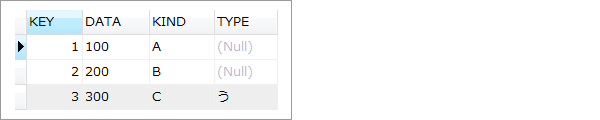
テーブルAとテーブルBを内部結合した上で、さらに3行目(KEY=3)だけに絞り込んだテーブルCを外部左結合でつなぎ、ピンクで着色した項目を抽出する場合を考えます。
内部結合と外部結合の複合
select A.KEY,A.DATA,B.KIND,C.TYPE
from A,B
left join C
on B.KEY=C.KEY and C.KEY='3'
where A.KEY=B.KEY;
~ 結果 ~
1-5.現場で要注意な結合
UNION、UNION ALL
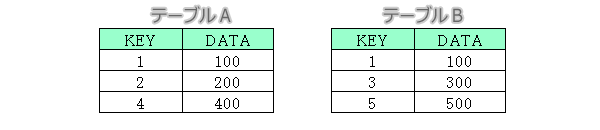
UNIONは同一項目数のテーブルを重複なしでマージします。UNION ALLは同一項目数のテーブルを重複があってもそのままマージします。
UNIONで抽出
select * from A
UNION
select * from B;
~ 結果 ~

UNION ALLで抽出
select * from A
UNION ALL
select * from B;
~ 結果 ~

問題は、結合したテーブルが順番に並ばないことです。表示の結果をそのまま使うのなら問題ありませんが、順番に並べ替えたい場合、サブクエリを使用するしかありません。しかし、この時点でプライマリーキー及びインデックスの効果がなくなってしまうので、並び替えに相当な時間がかかることになります。
サブクエリの疑似テーブル化
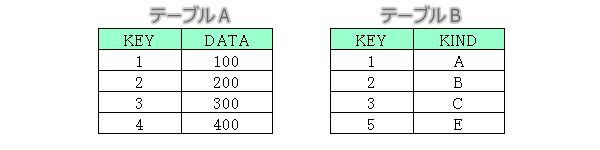
サブクエリはSQL文の中に、入れ子でSQL文を書く方法です。入れ子となるSQL文は()で囲み使用します。WHERE条件にサブクエリを指定する利用方法では問題はないのですが、サブクエリを疑似テーブルとして利用する場合は注意が必要です。
サブクエリを疑似テーブル化して抽出
select C.*,B.KIND
from (select * from A where A.KEY>=3) AS C,B
where C.KEY=B.KEY;
~ 結果 ~

この場合、サブクエリを疑似テーブル化しているのでプライマリーキー及びインデックスの効果がなくなります。上記の例ではAテーブル、Bテーブル両方のKEY項目にプライマリーキーを付与していても、Aテーブルをサブクエの疑似テーブル化することで、プライマリーキー及びインデックスの効果がなくなります。この効果がなくなったCテーブルとBテーブルを結合しているため、インデックスの効果のないテーブルとの結合となり、実行に相当な時間がかかることになります。複雑な抽出の場合、やむ負えずサブクエリの疑似テーブル化するケースも確かにありますが、できる限り工夫して疑似テーブル化しないようにするべきです。
1-6.現場でほぼ使わない結合
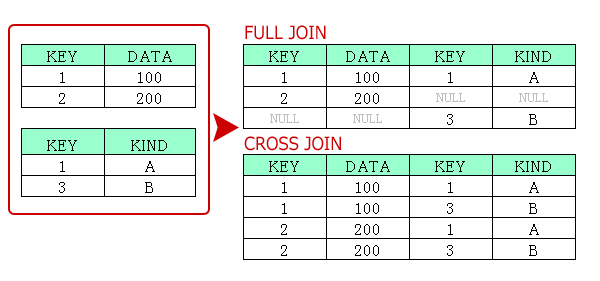
FULL JOIN(FULL OUTER JOIN)、CROSS JOIN
FULL JOIN、CROSS JOINは現場でほぼ使用しません。結合イメージは下図の通りですが、使い処はほぼないと思います。
※FULL JOINはMySQLでサポートされていません。
私の記憶ではCROSS JOINを現場で利用したのは2回だけ。
1回目:負荷テストで大量のダミーデータを急遽作成しなければならないという際に、CROSS JOINを使用しました。レコード数×レコード数でどんどん増えていくからです。
2回目:毎月全日付のレコードを作成しなけれいけなという際、あらかじめ1日~31日の全日付レコードを作成したテーブルを用意しておき、対象月の1レコードのみのテーブルと全日付のテーブルをCROSS JOINすることで全日付のレコードを生成しました。あとに月ごと29日、30日、31日のレコードを削除します。この方法だとカーソルでレコードを日付ごとインサートするより、又プログラム側から日付ごとインサートのループを掛けるより、結合のみで簡単にレコード生成できます。
NATURAL JOIN
NATURAL JOINは現場で使用してはいけません。NATURAL JOINは結合するテーブルの両方に同一の項目名があれば、ON条件を書かなくても自動で内部結合するというものです。
このため意図しない結合となることがあること、明示的に結合条件が示されないのでプログラムの視認性が悪くなること、これらの問題から現場での使用は避けるべきです。