今回は抽出の基本、一番単純な単一テーブルからの抽出についてまとめます。
実践でSQLを作成する場合、原則、プライマリーキーもしくはインデックスが作成されていない項目に対して抽出を行うことはご法度です。
もし、どうしてもプライマリーキーもしくはインデックスが作成されていない項目を抽出に指定しなければならない場合は、レスポンスを計測し本番環境で使用して問題がないか、十分に検討する必要があります。
単一テーブルからの抽出
単一テーブルから抽出するパターンです。
1-1.プライマリーキー、インデックスでの抽出比較
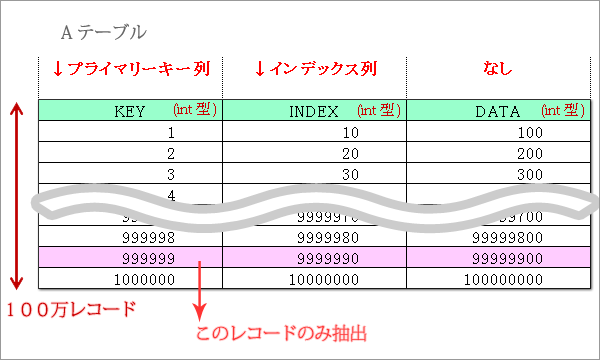
上図の通り、プライマリーキーでの抽出、インデックスでの抽出、なしの場合を考えます。
①プライマリーキーでの抽出
select *
from A
where KEY='999999';
②インデックスでの抽出
select *
from A
where INDEX='9999990';
③プライマリーキー、インデックスなしの抽出
select *
from A
where DATA='99999900';
ハードの性能に大きく左右されますが、Corei7(2.3GB)、メモリ4GBの環境で実行した結果、
・①が最速で0.000秒
・②は①より若干遅い0.015秒
・③は大きく速度低下して0.297秒
でした。
プライマリキー、インデックスのない項目で抽出するとレスポンスが悪く、原則、使用してはいけません。単一レコードの抽出ではこの程度ですが、複数テーブルの場合はさらにレスポンスが悪化します。
1-2.インデックスの効果(ガーディナリティ)
インデックスについては、項目の内容によってその速度効果が大きく異なります。これは一般的にガーディナリティと呼ばれるデータの重複度に依存します。
例えば有/無のみが入力される項目があったとして100万レコード存在する場合、内容としては100万レコードであれ有/無の2種類のみ。つまりグループ化した結果数は2。同じく重複度を示すガーディナリティは2ということになります。この2種類しかない項目にインデックスを付与しても、その速度改善は期待できません。
対して、100万レコードに各々違う値が入っている場合、ガーディナリティは100万。この項目にインデックスを付与すれば速度改善が期待できるということになります。
つまり、インデックスはガーディナリティの大きい場合に付与すると速度効果が期待できるものです。
各インデックスのガーディナリティは以下コマンドで確認することができます。
~ 結果 ~

1-3.項目の型が文字列の場合の抽出比較
上記1-1はint型の例でしたが、仮に全ての項目を文字列型(char、varchar等)にした場合、レスポンス速度は遅くなります。
①が0.410秒。②は0.416秒。③は0.461秒でした。
プライマリキーが文字列型であることは、現場では原則ありえませんが、インデックスの場合、どうしても文字列に使用しなければならない場面がありますが、あえて使用する場合にはレスポンスを十分チェックしなければなりません。
1-4.EXPLAINによるSQL分析
SQLの頭に「EXPLAIN」と入れることでそのSQLを評価することができます。大規模DBを扱ったことがある技術者は必ずこの評価を実施します。上記1-1の3パターンの結果は以下のように表示されます。
見るべき項目は「type」と「rows」です。
※このSQL分析については各DBMSによって方法が違います。これはMySQLのケースです。
①プライマリーキーでの抽出
EXPLAIN
select *
from A
where KEY='999999';
~ 結果 ~

「type」項目にconstと表示される場合はプライマリーキーが利用されている一番望ましい状態です。
②インデックスでの抽出
EXPLAIN
select *
from A
where INDEX='9999990';
~ 結果 ~

「type」項目にrefと表示される場合はインデックスが利用されている状態です。
③プライマリーキー、インデックスなしの抽出
EXPLAIN
select *
from A
where DATA='99999900';
~ 結果 ~

「type」項目にALLと表示される場合は何のキーも適用できていない改善が必要な状態です。
さらに「rows」項目に何レコードから抽出するかを表す概算レコード数が表示されます。
この場合、約100万レコードからの抽出となるので、レスポンスに時間がかかるということになります。
1-5.IN、LIKEによる抽出
抽出条件に、「=」ではなく、IN、LIKEを利用する場合を検証します。
①INでの抽出
EXPLAIN select *
from A
where KEY in ('1','2');
~ 結果 ~

「type」項目にrangeと表示される範囲検索の状態です。プライマリキーないしはインデックスキー項目を利用すれば速度的に問題ありません。ちなみに「rows」に2と表示されているのはINの後ろが()で囲まれており、サブクエリの状態となっているからです。()内にSQL文を書くこともできますが、この例では直接値を、2つ指定しています。これが「rows」に表示されています。
②LIKEでの抽出
EXPLAIN select *
from A
where KEY like '1%';
~ 結果 ~

LIKEは部分一致を指定する抽出です。例の「1%」は先頭が1から始まる前方一致で、1、10,11,100などが抽出されます。「%1」とすると後方一致。「%1%」とすると部分一致です。
LIKEの場合、「type」項目にALLと表示されます。つまり、何のキーも適用できていない状態です。どうしても使用しなければならない場合もあるかもしれませんが、速度が遅くなることを覚悟する必要があります。
1-6.サブクエリ(副問い合わせ)について
サブクエリとは、SQL文の中に、入れ子でSQL文を書く方法です。WHERE条件にサブクエリを指定して利用することができます。
サブクエリを利用した抽出
select *
from A
where KEY=(select KEY from A where INDEX='20');
この場合、内部的にはサブクエリの「select KEY from A where INDEX='20'」から抽出され、その結果が出た後、メインのクエリ「select * from A where KEY=(サブクエリの結果)」が実行されます。
従って、各々が適切にプライマリキーないしはインデックスを利用して抽出を行えば、2回に分けて適切なSQLが実行されることとなり、何ら、抽出速度に影響することはありません。
例では、サブクエリの評価を「=」で行いましたが、1-5のように、「IN」も利用できます。
1-7.その他抽出
~ LIMIT ~
LIMITはテーブルの範囲を指定して抽出するときに利用します。
LIMITによる範囲指定①
select *
from A
limit 0,10;
この例では、レコードの先頭(第1引数:0)から、10レコード(第2引数:10)抽出しています。尚、この順序ですが、テーブルのプライマリキー順です。抽出速度は非常に速いです。テーブル入っているそのままのレコードの並び順通り、範囲を指定して抽出しているだけだからです。当然、ORDER BY DESC(降順)を抽出条件に指定してしまうと、並べ替え作業が発生してしまうので抽出速度は悪化します。
LIMITによる範囲指定②
select *
from A
where INDEX<=1000
limit 10,10;
この例ではWHEREで条件を指定した上で、11レコード(第1引数:10)から、10レコード(第2引数:10)抽出しています。第1引数は0が1レコード目としますので、+1となります。
このLIMITは、高速で抽出できることを利用し、「>」「>>」ボタンを配置しながら大量のレコードを画面表示する画面インターフェースを作成する場合によく利用されます。
~ 正規表現の利用 ~
WHERE条件に正規表現を利用することが出来ます。
select *
from A
where INDEX regexp '^1';
利用することはできますが、1-5のLIKEと同じく、何のキーも適用できていない状態となりますので抽出速度は非常に遅いです。利用には十分注意が必要です。
~ WHERE 1=1のおまじない ~
WHERE条件の先頭にWHERE 1=1を記載することを、ルールとして決めている現場がたまにあります。そもそもWHERE 1=1という条件は必ずTRUEとなる条件です。書いても書かなくても抽出結果に変わりはないのですが、何故書くのでしょう。
select *
from A
where WHERE 1=1
and KEY='100'
and INDEX='1000'
and DATA='10000';
このように、AND条件が多くなると、WHEREの条件はインデントがずれているので、抽出条件として見落とされる可能性があります。これを避けるため、つまりプログラムの視認性のためにWHERE 1=1は現場で書かれています。