ここでまとめている内容は「データベーススペシャリスト試験」等で出題される、理論的なDBの概念であり、設計段階の話です。
特に、正規形についてはDB設計時に現場でもよく話題に挙がりますので、IT関係者の方はどんな立場であれ、概要は知っておくべきだと思います。
1.データモデル
実装前に作成する、データベース設計図のことです。
設計段階に沿って3種類のデータモデル
・概念データモデル
・論理データモデル
・物理データモデル
を順に作成します。
・概念データモデル
E-R図を用いた概念データモデルです。このモデルはDBMSに依存しません。
・論理データモデル
構築するDBMSの種類を考慮して、具体化するデータモデルです。
・階層モデル
・ネットワークモデル
・関係モデル / ドキュメント指向モデル
等が存在します。
RDBが主流なので「関係モデル」がメインですが、mongo dbの場合は「ドキュメント指向モデル」を作成します。
・物理データモデル
論理データモデルを元に、さらに具体的にインデックス、データサイズを加味した設計を行います。
データモデルごと要素の呼び名
下図のように、データモデルごと、その要素の呼び名が異なるので注意が必要です。
| 概念データモデル |
論理データモデル |
物理データモデル |
| E-R図 |
関係モデル |
テーブル構造 |
| エンティティ |
関係 |
テーブル |
| 属性 |
属性 |
列 |
| インスタンス |
タプル |
行 |
実際の現場でのデータモデルの扱い方
現場ごとに違いますし一概には言えないのですが、上記のような3段階の厳密なデータモデル作成を行っている現場は、見たことがありません。
多くの現場では、3段階をひとまとめに行い、その成果物としてテーブル、列とその型、キー、インデックス、テーブルごとの想定レコード数/増加数、テーブル関係のガーディナリティを記述したE-R図、テーブル定義書を作成します。そして、それら資料を元に、DBの容量やハードのスペックを決定します。
2.関数従属性
正規形を理解する上で必要となる前提知識です。
2つの属性AとBがある場合にAが決まればBも1つ決まる場合、BはAに関数従属しているといいます。
1つ決まるというのがポイントです。
この場合Aを決定項、Bを被決定項といい、 A → B と書きます。
複数の属性で1つ決まる場合、例えば2つの属性AとBがある場合にCが1つ決まる場合、CはA、Bに関数従属しているといい { A , B } → C と書きます。
なお、以下は推論則といい関数従属が常に成り立ちます。
推移律:A → B 、 B → C の関数従属成立時、 A → C が成立。推移関数従属ともいいます。
反射律: B が A の部分集合である場合当然 A → B
増加律: A → B が成立している場合 A , B に別の属性Cをおのおの持つ場合、{ A , C } → { B , C }が成立
完全関数従属と部分関数従属
完全関数従属
~ パターン1 ~
A → B
~ パターン2 ~
{ A , B } → C でありかつ A → C、B → C が成立しない場合。
いわゆる複合キーでユニークとなる場合です。
部分関数従属
{ A , B } → C でありかつ A → C、B → C が一方でも成立する場合。
3.キー属性
これも正規形を理解する上で必要となる前提知識です。
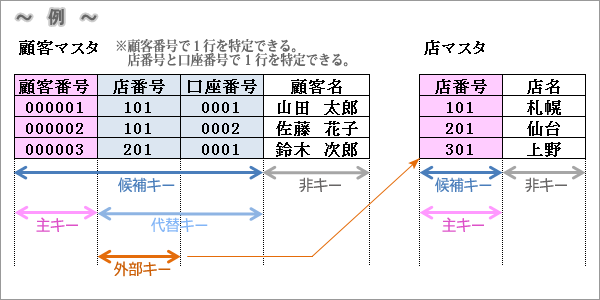
候補キー:
テーブルにおいて列または列の組み合わせによって、1行を特定できるものを候補キーと呼びます。
主キー:
候補キーの中で最も1行を特定するにふさわしい候補キーを、主キーと呼びます。
1テーブルに対し、1つだけ設定できるもので列の場合1つ、列の組み合わせの場合1組のみ設定可能です。(この場合は複合キーとも呼びます。)
代替キー:
主キーに選ばれなかった候補キーのことを、代替キーと呼びます。
非キー:
候補キー以外の列を非キーと呼びます。
外部キー:
他のテーブルの主キーや候補キーを参照する列を外部キーと呼びます。
4.正規形
正規形はデータベース内で、どの程度データの重複をなくし、一元的にデータを管理できるか、いわゆる正規化を示すデータ構造のレベルのことです。
非正規形→第一正規形→第二正規形→第三正規形とレベルが高くなるにつれ、正規化が進みますが、反面、データを問い合わせする際、データの場所が分散してしまうので、レスポンスが悪化します。
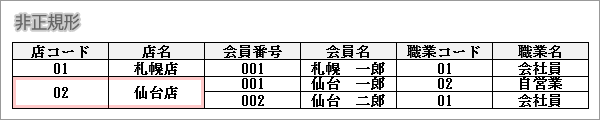
非正規形
下図のように行と列のデータが1対1とならないデータ、つまりデータベースで運用できないデータを非正規形といいます。
第一正規形
行と列のデータが1対1になっています。
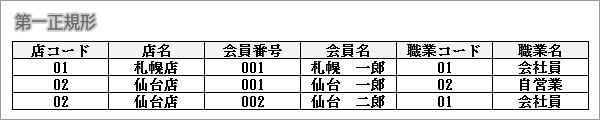
第一正規形の時点で主キーを付与します。この場合、主キーは「店コード」と「会員番号」の複合キーです。代替キーはありません。
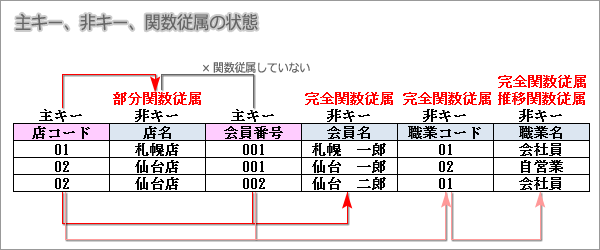
主キー、非キー、関数従属の状態を下図にまとめます。
このデータだけでは、「店名」が「店コード」の代替キーとなり得ますが、説明を簡素化するために、店コードの違う同店名が存在すると仮定し、店名は代替キーにできないとします。
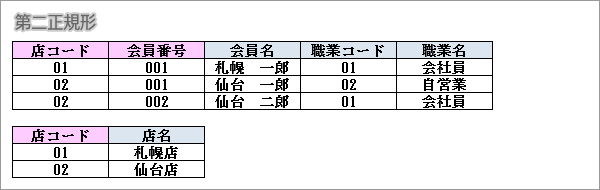
第二正規形
第一正規形でかつ非キー属性がすべての候補キーに対して完全関数従属している状態です。
この場合、部分関数従属となっている「店名」を別テーブルに移します。
第三正規形
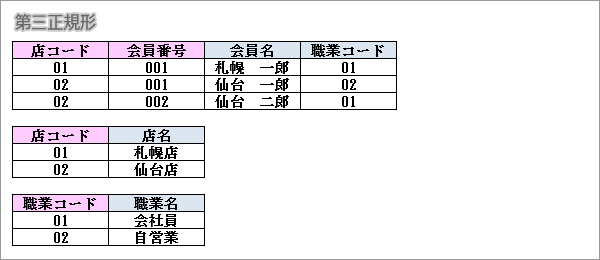
第二正規形でかつ候補キーと非キー属性に推移関数従属性がない関係です。
この場合、推移関数従属となっている「職業名」を別テーブルに移します。
その他正規形
以下、現場で実装されるケースは、ほとんどありません。
正規化するにつれ、データが複数のテーブルに分散してしまい、データ問い合わせのレスポンスが悪化する原因になります。
大規模データベースを運用する場合、第三正規形では正規化しすぎで、第二正規形、もしくは第一正規形で正規化をやめてしまう場合すらあります。このため、第三正規形以上の正規化を行う以下の正規形は、現状、現場で使用されることはほとんどありません。あくまで第三正規形以上はデータの重複をなくす学術的な理想論ということで認識して下さい。
ボイス・コッド正規形
第二正規形の変化形です。第二正規形は非キー属性がすべての候補キーに対して完全関数従属ですが、この非キー属性を「すべての属性」に置き換えます。第三正規形に進む前にさらにデータ重複を防ぐ目的でテーブル分割を行うことになります。
第四正規形
対称性のある多値従属性の分解、候補キーの分解を行います。
第五正規形
結合従属性を維持して分解、候補キーの分解を行います。